
Geth Freezer Files: Block Data Done Fast

At Superlunar we have been investigating how to quickly access the large and complex data contained within the Ethereum blockchain. In this post we will explore some of the data collection methods evaluated, detail the Geth freezer file format, and provide some pragmatic approaches for anyone interested in parsing Ethereum chain data quickly.
Our journey began while I was exploring some of the many UniswapV2 clones and looking for ways to fetch a complete list of all trades made of a given token pair. It’s possible to pay for this data, but the selection was always limited to only the major DEX’s and did not include everything I considered valuable. So, in an effort to extract what I needed, I started to develop a more custom approach using public RPC’s and working with the web3.py libraries to query the Ethereum JSON-RPC API for event data directly.
I quickly found that the JSON RPC was designed for mostly single call data requests and had difficulty fetching bulk historical data. I tried using the batch request system but found that public RPC nodes and even some free private RPCs would timeout when requesting the batch max of 5000 items per request. My next attempt was to try running a node to patch out any timeout being hit, but found that these bulk requests would then overload the CPU and disk of a node. This overload was especially pronounced if the block range being requested had a high volume of transactions. For these reasons I found this solution was too slow and practically impossible to use at any scale. Fetching the history of a single token pair could take 48 hours or more, if nothing broke or timed out in the interim. This was not the solution I was looking for.
The next two options on my list were the Geth GraphQL interface and the raw LevelDB format. By default, I decided against using the GraphQL interface because it would require network requests and be subject to all the same timeouts I had already encountered with RPC, in addition to possible performance bottlenecks within Geth itself.
Exploring the LevelDB format, I found it purpose built for how Geth stored the current state but the key-value system was keyed in such a way that it took far too many fetches to collect the transaction and log data for a given block efficiently. While looking for solutions to reduce lookups in the LevelDB format, I found Geth’s freezer implementation. It was so useful for mining data out of the Ethereum chain, it's worth exploring in more detail, sharing how the format works, and why we believe it's a powerful tool for anyone who wants to parse EVM chain data fast.
Freezer format to the rescue
The freezer format was introduced in Geth v1.9.0 in 2019 as a means to hold older state transition data. As the name suggests, Geth uses the freezer format for storing long term chain data, while continuing to hold the current state data in LevelDB. Because of the design goals and access patterns of the freezer, it also makes it the perfect data format for rapid linear reads which precisely fits my use case. The full freezer format implementation can be found in Geth here.
The freezer is composed of tables and rows like a database, but formatted as a collection of flat files in a directory. There are 5 classes of table, each representing different data types at a given block:
- `bodies`
- `headers`
- `receipts`
- `hashes`
- `diffs`
These files can be found on a full node at: `$DATADIR/geth/chaindata/ancient/`
Each table has an index file (.cidx) and a series of data files (.cdat). The index is used as a way to map a specific Ethereum block number to a data file and offset within that data file. Reading through a data file linearly, each Ethereum block has a 6 byte row created, the first 2 bytes of which are the data file number, ex:
`bodies.<FILENUMB>.cdat`
`bodies.0009.cdat`
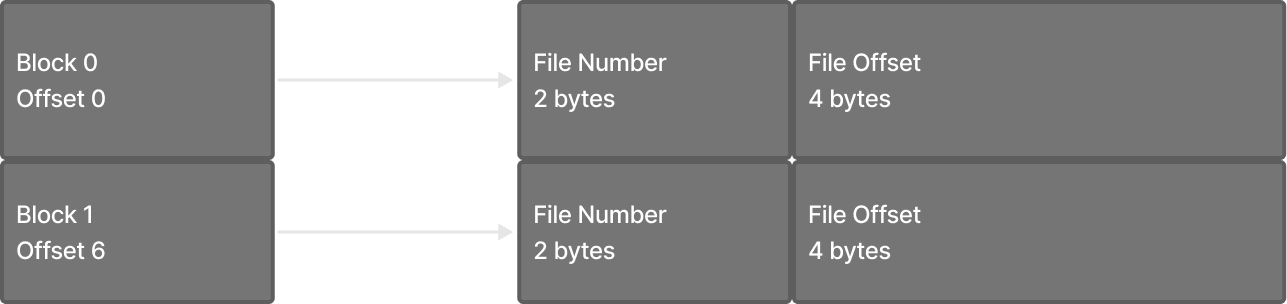
The index file makes jumping to the data of an arbitrary Ethereum block trivial because to find the index row of a given block one only has to do:
`block_numb * sizeof(index_row)`
Or more simply:
`block_number * 6`
The second part of the row is 4 bytes which represent the offset into the data file where a given block data resides. Within the data file at the given offset, the block data ‘row’ is represented as a <u class="tooltip" id="variable-size-block">variable size block of bytes</u> that are RLP encoded. If the file extension starts with a .c (which means “compressed”) the block data is snap compressed after RLP encoding.
Each `.cdat` file has a max size, which is defined as 2GB.
When the freezer cannot fit the next block data blob in the current data file, it creates another data file and places it there.
RLP structs
Within the snap compressed blobs is the RLP encoded data of a given table, the definitions of the structures can be found in the following locations:
At a high level, for the vast majority of data mining only the headers, bodies, and receipts tables are generally needed.
In the headers you will find the common block header data such as block number, gas_used, extra_data, miner address etc.
The bodies contain two arrays, the uncles (more blockheaders) and the transactions. The transaction array is a complicated one to parse due to Ethereum's trifurcation of the transaction type. There are 3 different types of transactions currently in Ethereum: Legacy, EIP-2930, and EIP-1559. In order to differentiate between them you need to:
- Check if the current transaction RLP object is a list, if it is, the TX is a Legacy transaction type.
- If not, check the first raw byte of the transaction data which indicates the transaction’s type as defined in the EIP’s (`0x01` for EIP-1559, and `0x02` for EIP-2930)
Next up is the receipts table which only contains a single entry consisting of an array of Receipt objects. These Receipt objects each contain cumulative gas, post_state, and log data. In order to map transactions to Receipts, the index of the Receipt object in the array maps to the transaction index.
Finally Logs is an array of Log objects for the given transaction. Each log entry contains an address, topics array, and data buffer.
Format Benefits
Using the indexing system of the .cidx files means that jumping to an arbitrary block and starting to read data from the structures encoded is exceedingly quick, meaning that it only takes a multiplication and memory read to locate the exact file and offset of a given block's data.
This makes the flat file format of the freezer nearly perfect for fast linear sweeps across the block data.
When thinking about how we might want to implement an efficient parser for carving block data out of freezer files, I found that a memory map pattern could be used very efficiently. By using a memory map we can linearly map each table (index file + current data file) into memory via mmap. At a max of 2GB for each data file, it is even possible to optimize further and use the MAP_POPULATE flag to mmap() so that the kernel will pre-populate all the contents of the mapping ahead of time, instead of page faulting, and reading in a new page as the process reads through the mapped file memory:
Where the MAP_POPULATE diverges flow within do_mmap().
While this approach creates a higher memory footprint: (2GB * `TABLE_COUNT`) + index_files_sizes, the footprint is one of constant size as long as each data file is munmap()’d once finished with. It also allows the kernel to perform all the disk access within a single syscall and as a linear read on the disk, making any storage system happy.
Further optimization may be realized through setting the MADV_HUGEPAGE via madvise() to try and hint the kernel to use huge_pages for the mapping, it’s possible however that your kernel might also promote mappings of this size automatically and so any explicit setting of MADV_HUGEPAGE would have no real effect.
The freezer is designed to be as efficient as possible in terms of disk storage and at the time of writing, a Geth mainnet node creates a freezer directory of approximately 303 GB, making storing this data relatively cheap and accessible compared to an archive node's multi-terabyte storage requirements.
Wrap up
When it comes to searching through Ethereum data at scale, Geth freezer files are an efficient way to do this without requiring the overhead and complexity of moving the data into a different database. As an additional benefit–since freezer files are used across most Ethereum-based chains, such as Polygon and Binance Smart Chain–this method is not just applicable to Ethereum mainnet.
As we approach the arrival of Eth2, it is important to highlight building blocks of the Ethereum technology stack such as the freezer format. Systems like these will hopefully make it possible to continue to scale Ethereum while providing us with a way to derive answers from complex blockchain data.





